|
глава 24 будущее tcp и его производительность tcp функционирует уже в течение многих лет и по slip каналам со скоростью 1200 бит в секунду и по ethernet. в 80-х и начале 90-х годов ethernet был основным типом канального уровня для tcp/ip. несмотря на то, что tcp корректно работает на скоростях больших, чем предоставляемые ethernet (телефонные линии t3, fddi и гигабитные сети, например), на повышенных скоростях начинают сказываться некоторые ограничения tcp. в этой главе рассматриваются некоторые предложения посвященные модификациям tcp, которые позволяют добиться максимальной пропускной способности на высоких скоростях. во-первых, мы рассмотрим механизм определения транспортного mtu, который мы уже упоминали раньше. сейчас мы подробно рассмотрим, как он функционирует с tcp. этот алгоритм позволяет tcp использовать mtu больше чем 536 для соединений по глобальным сетям, что, в свою очередь, повышает пропускную способность. затем мы рассмотрим каналы с повышенной пропускной способностью (long fat pipes), сети, имеющие большую емкость канала зависящую от полосы пропускания (bandwidth-delay product), и ограничения tcp, которые становятся существенными для этих сетей. здесь описаны две новые опции tcp, используемые для работы с каналами с повышенной пропускной способностью (long fat pipes): опция масштабирования окна (позволяет использовать окна tcp с максимальным размером больше чем 65535 байт) и опция временной марки. опция временной марки позволяет tcp осуществлять более аккуратный расчет rtt для сегментов данных, а также предоставляет защиту от перехода номеров последовательности через ноль, что может возникнуть на высоких скоростях. эти две опции определены в rfc 1323 [jacobson, braden, and borman 1992]. также мы рассмотрим t/tcp - модификацию tcp для транзакций. режим транзакций это характеристики коммуникации, при которых на запрос от клиента приходит отклик от сервера. основная задача t/tcp заключается в том, чтобы уменьшить количество сегментов, которыми обмениваются два участника соединения, при этом отпадает необходимость в трехразовом рукопожатии (three-way handshake) и четырех сегментах, которыми необходимо обменяться, чтобы закрыть соединение. при этом клиент получает отклик от сервера через время равное одному rtt плюс время, необходимое для обработки запроса. и самое замечательное в этих новых опциях - в характеристике определения транспортного mtu, опции масштабирования окна, опции временной марки и t/tcp - это то, что они совместимы с уже существующими реализациями tcp. новые системы, которые имеют эти опции, могут общаться с более ранними системами. за исключением дополнительных полей в icmp сообщении, которые могут быть использованы при определении транспортного mtu, новые опции должны быть реализованы только на конечных системах, которые хотят пользоваться их преимуществами. мы закончим эту главу рассмотрением публикаций, вышедших в настоящее время и имеющих отношение к производительности tcp. в разделе "транспортный mtu" главы 2 мы описали концепцию транспортного mtu (path mtu). это минимальный mtu в любой из сетей, по которым проходит маршрут между двумя хостами. при определении транспортного mtu в ip заголовке устанавливается бит "не фрагментировать" (df - don't fragment), что позволяет определить, необходимо ли какому-либо маршрутизатору на текущем маршруте фрагментировать ip датаграммы, которые мы посылаем. в разделе "icmp ошибки о недоступности" главы 11 мы показали icmp ошибку о недоступности, генерируемую маршрутизатором, которому необходимо перенаправить ip датаграмму с установленным битом df, когда mtu меньше чем размер датаграммы. в разделе "определение транспортного mtu с использованием traceroute" главы 11 мы показали версию программы traceroute, которая использует этот механизм, чтобы определить транспортный mtu к пункту назначения. в разделе "определение транспортного mtu при использовании udp" главы 11 мы видели, как udp определял транспортный mtu. в этом разделе мы просмотрим, как tcp использует этот механизм. это описано в rfc 1191 [mogul and deering 1990]. из всех систем, которые используются в этой книге (см. вступление), только solaris 2.x поддерживает определение транспортного mtu.
алгоритм определения транспортного mtu tcp работает следующим образом. когда соединение установлено, tcp использует минимальный mtu исходящего интерфейса или mss, объявленный удаленным концом, в качестве исходного размера сегмента. алгоритм определения транспортного mtu не позволяет tcp превосходить mss, объявленный удаленным концом. если удаленный конец не указал mss, то он устанавливается по умолчанию в значение равное 536. реализации могут сохранить информацию о транспортном mtu определенного канала, как мы говорили в разделе "показатели на маршрут" главы 21. после того как выбран исходный размер сегмента, во всех ip датаграммах, отправляемых tcp по этому соединению, установливается бит df. если промежуточному маршрутизатору необходимо фрагментировать датаграмму, в которой установлен бит df, он отбрасывает датаграмму и генерирует icmp ошибку "не могу фрагментировать" (can't fragment). это описано в разделе "icmp ошибки о недоступности" главы 11. если принята такая icmp ошибка, tcp уменьшает размер сегмента и повторяет передачу. если маршрутизатор сгенерировал новую icmp ошибку, размер сегмента может быть установлен в mtu следующей пересылки минус размеры ip и tcp заголовков. если возвратилась старая icmp ошибка, должно быть использовано следующее меньшее значение mtu (рисунок 2.5). когда осуществляются повторные передачи, вызванные этими icmp ошибками, окно переполнения не должно изменяться, вместо этого должен быть использован медленный старт. так как маршруты могут меняться со временем, по истечении определенного времени после последнего уменьшения транспортного mtu, можно попробовать большее значение (до величины минимального mss, объявленного удаленным концом, или mtu исходящего интерфейса). rfc 1191 рекомендует, чтобы этот временной интервал составлял примерно 10 минут. (мы видели в разделе "определение транспортного mtu при использовании udp" главы 11, что solaris 2.2 использует для этих целей 30-секундный тайм-аут.) используя обычное для работы в глобальных сетях значение mss по умолчанию равное 536, алгоритм определения транспортного mtu избегает фрагментации по промежуточным каналам с mtu меньшим чем 576 (что встречается довольно редко). также можно избежать фрагментации в локальных сетях, когда промежуточный канал (ethernet) имеет меньший mtu, чем сеть конечного пункта назначения (token ring). в процессе определения транспортного mtu (при работе в глобальных сетях с mtu большим чем 576), системы не должны использовать mss по умолчанию равный 536 байт для нелокальных пунктов назначения. предпочтительней выбирать mss равный mtu исходящего интерфейса (естественно, минус размер ip и tcp заголовков). (в приложении е мы увидим, что большинство реализаций позволяют системным администраторам изменить значение mss принятое по умолчанию.) пример увидеть, как происходит определение транспортного mtu, можно в том случае, когда промежуточный маршрутизатор имеет mtu меньше чем mtu интерфейсов конечных точек. на рисунке 24.1 показана топология для данного примера.
рисунок 24.1 топология для примера транспортного mtu.
мы установим соединение с хоста solaris (который поддерживает механизм определения транспортного mtu) на хост slip. установки идентичны тем, которые использованы для примера определения транспортного mtu в случае udp (рисунок 11.13), однако здесь мы установили mtu интерфейса на slip равный 552, вместо его обычного значения 296. это заставляет slip объявить mss равный 512. мы оставили mtu = 296 на slip канале на bsdi, поэтому tcp сегменты, размером больше чем 256, должны быть фрагментированы. посмотрим, как механизм определения транспортного mtu на solaris обработает подобную ситуацию. запустим программу sock на хосте solaris и осуществим одну запись величиной 512 байт на discard сервис хоста slip: solaris % sock -i -n1 -w512 slip discard
на рисунке 24.2 мы показали вывод команды tcpdump, полученный на slip интерфейсе хоста sun. значение mss в строках 1 и 2 как раз такое, как и ожидалось. затем мы видим, что solaris отправил сегмент размером 512 байт (строка 3), содержащий 512 байт данных и подтверждение на syn. (мы видели эту комбинацию ack вместе с syn в первом сегменте данных в упражнении 9 главы 18.)
рисунок 24.2 вывод команды tcpdump для определения транспортного mtu.
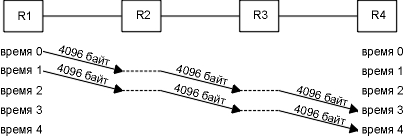
в строке 4 генерируется icmp ошибка, и мы видим, что маршрутизатор bsdi генерирует новую icmp ошибку, содержащую mtu исходящего интерфейса. так случилось, что перед тем, как эта ошибка вернулась на хост solaris, был отправлен fin (строка 5). так как slip не получил 512 байт данных, отброшенных маршрутизатором bsdi, и не ожидает этого номера последовательности (513), он отправляет ожидаемый номером последовательности (1) в строке 6. в это время icmp ошибка вернулась на solaris, и было повторно передано 512 байт данных в двух сегментах размером 256 байт (строки 7 и 9). оба сегмента отправлены с установленным битом df, так как дальше за маршрутизатором bsdi может быть еще один маршрутизатор, у которого mtu еще меньше. была осуществлена довольно долгая передача (она заняла примерно 15 минут), и после перехода от исходного размера сегмента равного 512 байт к сегментам размером 256 байт, solaris уже больше никогда не пытался отправить сегменты большего размера. народная мудрость гласит, что лучше использовать большие пакеты [mogul 1993, sec.15.2.8], потому что отправка меньшего количества больших пакетов "дешевле", чем отправка большего количества маленьких пакетов. (подразумевается, что пакеты не настолько велики, чтобы вызвать фрагментацию.) не все согласны с этим положением [bellovin 1993]. представьте себе следующий пример. мы посылаем 8192 байта через четыре маршрутизатора, каждый из которых подключен к телефонной линии t1 (1544000 бит/сек). во-первых, мы используем два пакета размером 4096 байт, как показано на рисунке 24.3.
рисунок 24.3 отправка двух пакетов размером 4096 байт через четыре маршрутизатора.
основная проблема заключается в том, что маршрутизаторы это устройства, которые работают по принципу "сохранить и перенаправить". они обычно получают входящий пакет целиком, проверяют на правильность ip заголовок, включая контрольную сумму ip, принимают решение о маршрутизации и затем начинают отправку исходящего пакета. на этом рисунке мы предположили идеальный случай, когда на операции, осуществляемые в маршрутизаторе, время не тратится, (горизонтальные пунктирные линии). тем не менее, на отправку всех 8192 байт от r1 до r4 будет истрачено четыре отрезка времени. время на каждую пересылку будет составлять
[(4096 + 40 байт) x 8 бит/байт]/1544000 бит/сек = 21,4 миллисекунды на пересылку
(ip и tcp заголовки составляют 40 байт.) полное время, которое тратится на отправку данных, состоит из количества пакетов плюс количество пересылок минус один и составляет четыре отрезка времени или 85,6 миллисекунды. каждый канал остается неиспользованным в течение двух отрезков времени или 42,8 миллисекунды. на рисунке 24.4 показано что произойдет, если мы пошлем 16 пакетов размером 512 байт.
рисунок 24.4 отправка 16 пакетов размером 512 байт через четыре маршрутизатора.
это передача займет больше отрезков времени, однако каждый отрезок короче, так как отправляются пакеты меньшего размера.
[(512 + 40 байт) x 8 бит/байт]/1544000 бит/сек = 2,9 миллисекунды на пересылку
сейчас полное время составляет (18 x 2,9) = 52,2 миллисекунды. каждый канал снова не занят в течение двух отрезков времени, что сейчас составляет 5,8 миллисекунды. в этом примере мы игнорировали время, которое необходимо для того, чтобы вернулось подтверждение (ack), также мы проигнорировали время, необходимое для установления и разрыва соединения, и не приняли во внимание то, что по каналам может двигаться и другой траффик. тем не менее, расчеты в [bellovin 1993] указывают, что отправка больших пакетов всегда эффективней. однако, для различных сетей требуются более подробные исследования. каналы с повышенной пропускной способностью (long fat pipes) в разделе "пропускная способность для неинтерактивных данных" главы 20 мы сказали, что емкость соединения можно рассчитать следующим образом
емкость (бит) = ширина полосы (бит/сек) x время возврата (сек)
и назвали это емкость канала в зависимости от полосы пропускания. иногда эта величина называется размером канала между двумя точками. существующие ограничения tcp начинают влиять на производительность по мере увеличения емкости каналов. на рисунке 24.5 показаны некоторые значения для различных типов сетей.
рисунок 24.5 емкость канала для различных сетей.
мы показали емкость канала в байтах, потому что именно так эта величина обычно рассчитывается на каждом конце соединения для определения размеров буферов и размеров окон. сети с большой емкостью канала называются сетями с повышенной пропускной способностью (lfn - long fat networks, произносится как "elephant(s)", elephant (англ.) - слон), а tcp соединения, работающие на lfn, называются каналами с повышенной пропускной способностью (long fat pipe). возвращаясь назад к рисункам 20.11 и 20.12, можно сказать, что эти каналы могут быть расширены в горизонтальном направлении (большие rtt) или в вертикальном направлении (большая ширина полосы передачи) или в обоих направлениях. однако, с подобными каналами с повышенной пропускной способностью возникают некоторые проблемы.
положение вещей меняется, когда скорости в сетях достигают гигабитов. [partridge 1994] описывает гигабитные сети более подробно. здесь мы рассмотрим различие между задержкой (латенсией) и шириной полосы [kleinrock 1992]. представьте себе процесс отправки файла размером 1 миллион байт через соединенные штаты, с предполагаемой латенсией равной 30 миллисекундам. на рисунке 24.6 показаны два сценария, верхний соответствует использованию телефонной линии t1 (1544000 бит/сек), а нижний подразумевает использование сети 1 гигабит/сек. время показано по оси ох, (отправитель находится слева, а получатель справа), а емкость показана по оси oy. закрашенный прямоугольник на обоих рисунках - это 1 миллион байт, который необходимо отправить.
рисунок 24.6 отправка файла размером 1 мбайт по сетям с 30-миллисекундной латенсией.
на рисунке 24.6 показано состояние обеих сетей через 30 миллисекунд. в обеих сетях первый бит данных достиг удаленного конца через 30 миллисекунд (латенсия), однако в случае сети t1 (емкость канала - 5790 байт), 994210 байт все еще находятся у отправителя, ожидая того, что они будут отправлены. емкость гигабитной сети, составляет 3750000 байт, поэтому файл целиком занимает всего лишь около 25% канала. последний бит файла достигает получателя через 8 миллисекунд после первого бита. полное время передачи файла по сети t1 составляет 5,211 секунды. если мы увеличить ширину полосы пропускания, например, с использованием сети t3 (45000000 бит/сек), полное время уменьшится до 0,208 секунды. увеличение ширины полосы в 29 раз уменьшает полное время в 25 раз. в случае гигабитной сети полное время, необходимое на передачу файла, составляет 0,038 секунды: 30-миллисекундная латенсия плюс 8 миллисекунд на реальную передачу файла. предположим, мы можем увеличить ширину полосы пропускания до 2 гигабит/сек, однако в этом случае мы уменьшим полное время передачи до всего лишь 0,034 секунды: та же самая 30-миллисекундная латенсия плюс 4 миллисекунды на передачу файла. таким образом, удвоение полосы передачи, уменьшает полное время всего лишь на 10%. в случае гигабитных скоростей мы уже ограничены латенсией, а не шириной полосы. латенсия определяется скоростью света, и мы не можем ее уменьшить (если, конечно, эйнштейн был прав). влияние фиксированной латенсии становится еще более ощутимым (в отрицательную сторону), когда мы решаем установить или закрыть соединение. в случае гигабитных сетей на некоторые сетевые проблемы приходится взглянуть с другой точки зрения. опция масштабирования окна увеличивает определение окна tcp с 16 до 32 бит. вместо того чтобы изменять tcp заголовок, для того чтобы поместить в него окно большего размера, заголовок все так же содержит 16-битное значение, а опция определяет операцию масштабирования этого 16-битного значения. после чего tcp использует "реальный" размер окна внутри себя как 32-битное значение. мы видели пример использования этой опции на рисунке 18.20. 1-байтовый сдвиговый счетчик находится в диапазоне от 0 (нет масштабирования) до 14. максимальное значение равное 14 соответствует окну размером 1.073.725.440 байт (65535 x 214). эта опция может появиться только в сегменте syn; таким образом, коэффициент масштабирования определяется в каждом направлении при установлении соединения. чтобы включить масштабирование окна, оба конца должны активизировать опцию в своих сегментах syn. сторона, осуществляющая активное открытие, посылает опцию в своем syn, однако сторона, осуществляющая пассивное открытие, может послать опцию, только если эта опция установлена в полученном syn. коэффициент масштабирования может быть различен для каждого направления. если сторона, осуществляющая активное открытие, устанавливает ненулевой коэффициент масштабирования, однако не получает опцию масштабирования окна с удаленного конца, эта сторона устанавливает свой сдвиговый счетчик отправки и приема в 0. таким образом добиваются совместимости новых систем со старыми, не поддерживающими эту опцию. требования к хостам host requirements rfc требуют, чтобы tcp принимал эту опцию в любом сегменте. (единственная заранее определенная опция, максимальный размер сегмента, может появиться только в сегментах syn.) также этот документ требует, чтобы tcp игнорировал любые опции, которые он не понимает. это легко осуществимо, так как все новые опции имеют поле длины (рисунок 18.20).
представьте, что мы используем опцию масштабирования окна со сдвиговым счетчиком равным s для отправки и со сдвиговым счетчиком равным r для приема. в этом случае каждые 16 бит объявленного окна, которые мы получаем от удаленного конца, сдвигаются влево на r бит, чтобы получить реальный размер объявленного окна. каждый раз, когда мы отправляем объявление окна на удаленный конец, мы берем реальный 32-битный размер окна, сдвигаем его вправо на s бит, помещаем получившийся результат (16-битное значение) в tcp заголовок. tcp автоматически выбирает значение сдвигового счетчика, основываясь на размере приемного буфера. размер приемного буфера устанавливается системой, однако приложению дается возможность изменить его. (мы обсудили приемный буфер в разделе "размер окна" главы 20.) пример если мы инициируем соединение с использованием программы sock с хоста 4.4bsd vangogh.cs.berkeley.edu, то можем увидеть, как tcp рассчитывает коэффициент масштабирования окна. приведенный ниже интерактивный вывод показывает два последовательных запуска программы, причем в первом случае устанавливается приемный буфер размером 128000 байт, а во втором приемный буфер установлен в 220000 байт:
на рисунке 24.7 показан вывод команды tcpdump для этих двух соединений. (мы удалили последние 8 строк для второго соединения, потому что в них нет ничего нового.)
рисунок 24.7 пример опции масштабирования окна.
в строке 1 vangogh объявляет окно размером 65535 и указывает опцию масштабирования окна со сдвиговым счетчиком равным 1. это объявленное окно имеет максимально возможное значение, однако оно меньше чем размер приемного буфера (128000), потому что поле окна в сегменте syn никогда не масштабируется. коэффициент масштабирования равный 1 означает, что vangogh хочет объявить окна размером до 131070 (65535 x 21). это соотносимо с размером приемного буфера (128000). так как bsdi не отправлял опцию масштабирования окна в своем syn (строка 2), эта опция не используется. обратите внимание на то, что vangogh и дальше продолжает использовать максимально возможный размер окна (65535) для соединения. для второго соединения vangogh устанавливает сдвиговый счетчик в значение 2, а это означает, что он собирается отправить объявления окна размером до 262140 (65535 x 22), то есть больше чем размер приемного буфера (220000). опция временной марки (timestamp) позволяет отправителю поместить значение временной марки в каждый сегмент. получатель возвращает это значение в подтверждении, что позволяет отправителю рассчитать rtt при получении каждого ack. (мы должны сказать " каждый ack", а не "каждый сегмент", так как tcp обычно подтверждает несколько сегментов с помощью одного ack.) мы сказали, что большинство современных реализаций рассчитывают одно rtt на окно, что вполне достаточно, если окно содержит 8 сегментов. однако в случае, если окно имеет большие размеры, требуется лучший расчет rtt. раздел 3.1 в rfc 1323 объясняет причины, по которым требуется лучшая оценка rtt при больших размерах окна. обычно rtt измеряется с помощью сигнала данных (сегмент данных), с небольшой частотой (один раз на окно). когда в окне 8 сегментов, скорость сигналов составляет одну восьмую скорости данных, что вполне приемлемо, однако когда в окне 100 сегментов, скорость сигналов составляет 1/100 от скорости данных. при этом rtt может быть рассчитано некорректно, что, в свою очередь, может вызвать повторные передачи, в которых нет необходимости. если сегмент потерян, все становится еще хуже.
на рисунке 18.20 показан формат опции временной марки. отправитель помещает 32-битное значение в первое поле, а получатель отражает его эхом в поле отклика. tcp заголовки, содержащие эту опцию, увеличиваются с обычных 20 байт до 32-х. временная марка - монотонно увеличивающееся значение. так как получатель отражает то, что он получает, его не интересуют конкретные значения временных марок. эта опция не требует какой-либо формы синхронизации часов между двумя хостами. rfc 1323 рекомендует, чтобы значение временной марки увеличивалось на единицу в диапазоне от 1 миллисекунды до 1 секунды. 4.4bsd увеличивает временную марку каждые 500 миллисекунд, и эта временная марка сбрасывается в 0 при перезагрузке.
обратитесь к рисунку 24.7. разница временных марок между сегментом 1 и сегментом 11 составляет 89 промежутков размером по 500 миллисекунд. что составляет 44,4 секунды.
эта опция устанавливается при открытии соединения таким же образом, как и опция масштабирования окна, которую мы рассмотрели в предыдущем разделе. сторона, осуществляющая активное открытие, устанавливает опцию в своем syn. только если опция получена в syn с удаленного конца, она может быть установлена в следующих сегментах. мы видели, что получающий tcp не должен подтверждать каждый полученный сегмент данных. если получатель отправляет ack, подтверждающий два принятых сегмента данных, которая из принятых временных марок отправляются назад в поле эха отклика на временную марку? чтобы минимизировать количество состояний, обрабатываемых на каждом конце, только одно единственное значение временной марки используется для каждого соединения. алгоритм, по которому выбирается момент, когда необходимо обновить это значение, довольно прост. tcp всегда знает значение временной марки, которое необходимо послать в следующем ack (переменная с именем tsrecent), и номер последовательности подтверждения последнего ack, который был отправлен (переменная с именем lastack). номер последовательности это следующий номер последовательности, который ожидает принять получатель. когда прибывает сегмент, содержащий байт, номер которого хранится в lastack, значение временной марки из этого сегмента сохраняется в tsrecent. когда бы ни была отправлена опция временной марки, tsrecent отправляется в поле эха отклика временной марки, а поле номера последовательности сохраняется в lastack.
этот алгоритм обрабатывает два следующих случая:
помимо того, что опция временной марки позволяет лучше рассчитывать rtt, она также предоставляет получателю способ избежать получения старых сегментов и воспринятия их как части существующих сегментов данных. это описывается в следующем разделе. paws: защита от перехода номеров последовательности через ноль представим tcp соединение, использующее опцию масштабирования окна, с максимально возможным окном, 1 гигабайт (230). (самое большое окно даже меньше чем это, 65535 x 214, а не 216 x 214, однако это не должно влиять на наши рассуждения.) также представьте, что используется опция временной марки, и что значение временной марки, назначенное отправителем, увеличивается на единицу для каждого отправляемого окна. (это достаточно устаревший способ. обычно значение временной марки увеличивается значительно быстрее.) на рисунке 24.8 показан поток данных между двумя хостами, возникающий при передаче 6 гигабайт. чтобы избежать большого количества десятизначных цифр, мы используем запись g, что означает умножение на 1.073.741.824. мы также используем форму записи из tcpdump, где j:k означает байты от j до k-1, включая байт k-1.
рисунок 24.8 передача 6 гигабайт в шести 1-гигабайтных окнах.
32-битный номер последовательности перешел через ноль между моментами времени d и e. мы предположили, что один сегмент потерялся в момент времени b и был передан повторно. также мы предположили, что потерянный сегмент повторно появился в сети в момент времени f. разница во времени между моментами, когда сегмент был потерян и появился повторно, меньше чем msl; иначе сегмент должен быть отброшен каким-либо маршрутизатором по истечению его ttl. как мы упоминали ранее, такая проблема возникает только на высокоскоростных соединениях, где старые сегменты могут повторно появиться и содержать номер последовательности, который в настоящее время передается. также мы можем видеть из рисунка 24.8, что использование временной марки решает эту проблему. получатель рассматривает временную марку как 32-битное расширение к номеру последовательности. так как потерянный сегмент, повторно появившийся в момент времени f, имел временную марку равную 2, что меньше чем самая последняя приемлемая временная марка (5 или 6), он отбрасывается алгоритмом paws. алгоритм paws не требует какой-либо формы синхронизации времени между отправителем и получателем. все что необходимо получателю это то, чтобы значение временной марки монотонно увеличивалось и увеличивалось по крайней мере на единицу для каждого нового окна. t/tcp: расширение tcp для транзакций tcp предоставляет транспортный сервис виртуальных каналов (virtual-circuit). существуют три определенные фазы в жизни соединения: установление соединения, передача данных и разрыв соединения. приложения, осуществляющие удаленный терминальный доступ и передачу файлов, хорошо приспособлены для работы с сервисом виртуальных каналов. помимо этого существуют приложения, разработанные для использования сервиса транзакций. транзакция это запрос от клиента, за которым следует отклик от сервера, со следующими характеристиками: необходимо избежать лишних действий при установлении и разрыве соединения. когда это возможно, необходимо отправлять один пакет с запросом и получать один пакет с откликом. латенсия должна быть уменьшена до rtt плюс spt, где rtt это время возврата, а spt это время необходимое серверу для обработки запроса. сервер должен определять дублированные запросы и не повторять транзакцию, когда прибывает дублированный запрос. (другими словами, сервер не обрабатывает запрос снова. он должен послать назад сохраненный отклик, соответствующий запросу.) одно из рассмотренных нами приложение, использующее этот тип сервиса - система имен доменов (dns, глава 14). надо отметить, что dns сервер не осуществляет повторную обработку дублированных запросов. в настоящее время разработчики приложений имеют выбор: tcp или udp. tcp предоставляет слишком много характеристик для транзакций, а udp - слишком мало. обычно приложения строятся с использованием udp (чтобы избежать перегруженности характеристиками свойственной tcp соединениям), при этом большинство требуемых характеристик (динамические тайм-ауты и повторные передачи, избежание переполнения и так далее) помещаются внутрь приложений, и для каждого приложения их приходится делать заново. оптимальное решение - это транспортный уровень, который включает в себя эффективную обработку транзакций. протокол транзакций, который мы описываем в этом разделе, называется t/tcp. протокол определен в rfc 1379 [braden 1992b] и [braden 1992c]. для большинства tcp реализаций требуются 7 сегментов, чтобы открыть и закрыть соединение (см. рисунок 18.13). здесь добавляются еще три сегмента: один с запросом, другой с откликом и подтверждением на запрос и третий с подтверждением на отклик. если в сегменты добавлены дополнительные управляющие биты - а именно, первый сегмент содержит syn, запрос клиента, и fin - клиенту все кажется, что имеют место лишние действия, которые выражается в виде удвоенного значения rtt плюс spt. (отправка syn вместе с данными и fin разрешена; сможет ли tcp обработать подобную ситуацию корректно - это уже другой вопрос.) еще одна проблема с tcp это состояние time_wait, которое требует ожидания в течение 2msl. как показано в упражнении 14 главы 18, это ограничивает скорость транзакций между двумя хостами на величине примерно 268 в секунду. две модификации, необходимые для tcp, чтобы обрабатывать транзакции, заключаются в том, чтобы избежать трехразового рукопожатия и сократить состояние time_wait. t/tcp избегает трехразового рукопожатия с использованием ускоренного открытия: t/tcp назначает каждому соединению номер в соответствии с 32-битным счетчиком соединений (cc - connection count), вне зависимости от того, осуществляется ли активное или пассивное открытие. значение cc хоста назначается из общего счетчика, который увеличивается на единицу при каждом его использовании. каждый сегмент между двумя хостами, использующими t/tcp, включает новую tcp опцию, которая называется cc. эта опция имеет длину 6 байт и содержит 32-битное значение cc отправителя для соединения. хост имеет кэш для каждого хоста, с которым был осуществлен обмен. в кэше содержится значение cc из последнего полученного от этого хоста сегмента syn. когда опция cc получена в исходном syn, получатель сравнивает значение с сохраненным значением для этого отправителя. если полученное cc больше чем кэшированное cc, syn новый, и любые данные, находящиеся в сегменте, передаются принимающему приложению (серверу). соединение называется наполовину синхронизированным. если полученное cc не больше чем кэшированное cc, или если принимающий хост не имеет кэшированного cc для этого клиента, осуществляется стандартное трехразовое рукопожатие tcp. syn, ack сегмент в отклике на первоначальный syn, отражает эхом полученное значение cc в другой новой опции, которая называется cc эхо или ccecho. с помощью значения cc в сегментах, не содержащих syn, определяются и отбрасываются любые дублированные сегменты от предыдущих воплощений того же самого соединения. благодаря ускоренному открытию отпадает необходимость в трехразовом рукопожатии, за исключением того случая когда оба, и клиент, и сервер, вышли из строя и перезагрузились. однако мы платим за это тем, что сервер должен помнить последний полученный cc от каждого клиента. состояние time_wait становится короче, потому что расчет задержки time_wait осуществляется динамически, на основании измеренного rtt между двумя хостами. задержка time_wait устанавливается в rto умноженное на 8 (rto - значение тайм-аута повторной передачи, глава 21, раздел "определение времени возврата"). с использованием этих характеристик, минимальная последовательность транзакций заключается в обмене тремя сегментами: от клиента к серверу, осуществляется при активном открытии: syn-клиента, данные от клиента (запрос), fin-клиента и cc-клиента. tcp сервер, осуществляющий пассивное открытие, получает эти сегменты и если cc-клиента больше чем кэшированный cc для этого клиента, данные клиента передаются приложению сервера, которое обрабатывает запрос. от сервера к клиенту: syn-сервера, данные сервера (отклик), fin-сервера, подтверждение на fin-клиента, cc-сервера и ccecho на cc-клиента. так как подтверждения tcp - обобщающие, ack на fin-клиента подтверждает syn-клиента, данные и fin. когда tcp клиент получает этот сегмент, он передает отклик приложению клиента. от клиента к серверу: ack на fin-сервера, который подтверждает syn-сервера, данные и fin. время отклика клиента на его запрос составляет rtt плюс spt. в реализации этой tcp опции существует множество особенностей, которые мы кратко рассмотрим:
одна из основных особенностей t/tcp заключается в том, что для его реализации требуется минимальный набор изменений к существующему протоколу, что, в свою очередь, обеспечивает совместимость с более ранними версиями существующих реализаций. он также использует все преимущества существующих характеристик tcp (динамические тайм-ауты и повторные передачи, предотвращение переполнения и так далее), вместо того чтобы заставлять приложения заботиться об этом. альтернативный протокол транзакций - vmtp, versatile message transaction protocol. он описан в rfc 1045 [cheriton 1988]. в отличие от t/tcp, который вносит небольшое количество расширений в существующий протокол, vmtp это транспортный уровень в целом, который использует ip. vmtp занимается определением ошибок, повторными передачами и предотвращением дублирования. он также поддерживает групповые способы рассылки. цифры, которые публиковались в середине 80-х годов, показывали пропускную способность tcp по ethernet где-то в районе 100000-200000 байт в секунду. (в разделе 17.5 [stevens 1990] приводятся эти цифры.) с того времени многое изменилось. современное аппаратное обеспечение (рабочие станции и быстрые персональные компьютеры) обеспечивает передачу 800000 байт в секунду и больше. стоит наверное рассчитать максимальную теоретически возможную пропускную способность, которую мы можем получить с tcp на ethernet 10 мбит/сек [warnock 1991]. на рисунке 24.9 показаны данные, необходимые для подобного расчета. на этом рисунке показано полное количество байт, необходимое при обмене сегментами данных полного размера, и ack.
рисунок 24.9 размеры полей для ethernet при расчете максимальной теоретически возможной пропускной способности.
мы должны сделать расчет для всех составляющих: преамбула, байты заполнения, которые добавляются к подтверждению, контрольная сумма, и минимальный промежуток между пакетами (9,6 микросекунды, что равно 12 байтам при скорости 10 мбит/сек). во-первых, мы предположим, что отправитель передает два полноразмерных сегмента данных, после чего получатель отправляет ack на эти два сегмента. максимальная пропускная (throughput) способность (для пользовательских данных) будет равна
throughput = [(2 x 1460 байт)/(2 x 1538 + 84 байта)] x [(10.000.000 бит/сек)/(8 бит/байт)] = 1.155.063 байт/сек
если окно tcp открыто на его максимальный размер (65535, опция масштабирования окна не используется), это позволяет отправить окно размером в 44 сегмента, каждый из которых размером 1460 байт. если получатель отправляет ack на каждый 22-й сегмент, расчет будет следующим
throughput = [(22 x 1460 байт)/(22 x 1538 + 84 байта)] x [(10.000.000 бит/сек)/(8 бит/байт)] = 1.183.667 байт/сек
это теоретический предел, при расчете которого сделаны некоторые допущения: не произойдет коллизии (столкновения) между ack, отправленным получателем, и одним из сегментов отправителя; отправитель может передать два сегмента с минимальным промежутком ethernet; и получатель может сгенерировать ack внутри минимального промежутка ethernet. несмотря на оптимизм, который так и пышет из этих цифр, [warnock 1991] приводит измеренную скорость равную 1.075.000 байт/сек по ethernet, со стандартной многопользовательской рабочей станцией (быстрая рабочая станция), что составляет примерно 90% от теоретического значения. что касается более быстрых сетей, таких как fddi (100 мбит/сек), [schryver 1993] рассказывает, что три поставщика демонстрировали tcp поверх fddi со скоростью в диапазоне от 80 до 98 мбит/сек. в случае, когда доступна большая ширина полосы пропускания, [borman 1992] сообщает, что было получено до 781 мбит/сек между двумя компьютерами cray y-mp по каналу hippi 800 мбит/сек, и 907 мбит/сек между двумя процессами с использованием loopback интерфейса на компьютере cray y-mp. следующие практические ограничения применимы для всех реальных сценариев [borman 1991].
смысл всех приведенных выше цифр заключается в том, что реальный верхний предел того, насколько быстро может работать tcp, определяется размером tcp окна и скоростью света. в заключение, можно, ссылаясь на [partridge and pink 1993], заявить, что большинство проблем с производительностью протокола заключается в основном в реализациях, а не во внутренних или наследуемых ограничениях самого протокола. в этой главе рассмотрено пять новых характеристик tcp: определение транспортного mtu, опция масштабирования окна, опция временной марки, защита от перехода через 0 номера последовательности и улучшенная обработка транзакций с использованием tcp. мы видели, что три средние опции требуются для оптимальной производительности в каналах с повышенной пропускной способностью - в сетях с большой емкостью. определение транспортного mtu позволяет tcp использовать окна больше, чем окно по умолчанию равное 536, для нелокальных соединений, когда транспортный mtu больше. это может улучшить производительность. опция масштабирования окна воспринимает максимальный размер tcp окна от 65535 байт до сверх 1 гигабайта. опция временной марки позволяет аккуратно засечь время для нескольких сегментов и также позволяет получателю предоставить защиту против перехода номера последовательности через 0 (paws). это очень важно для высокоскоростных соединений. эти новые опции tcp обсуждаются хостами при установлении соединения и игнорируются более старыми системами, которые не понимают их, позволяя более новым системам нормально функционировать с более старыми системами. расширение tcp для транзакций, t/tcp, позволяет ограничить общение клиент-сервер запрос-отклик всего тремя сегментами. это позволяет избежать трехразового рукопожатия и уменьшить продолжительность состояния time_wait с помощью кэширования небольшого количества информации для каждого хоста, с которым установлено соединение. при этом флаги syn и fin передаются в сегментах данных. мы завершили главу рассмотрением производительности tcp, так как до сих пор существует огромное количество "фольклора", который далек от истины, о том, как может и насколько быстро должен работать tcp. для хорошо настроенных и отлаженных реализаций, которые используют более новые характеристики, описанные в этой главе, производительность tcp ограничивается только максимальным окном размером в 1 гигабайт и скоростью света (то есть, временем возврата). упражнения
|