|
из рисунка 1.4 видно, что основная задача канального уровня в семействе протоколов tcp/ip - посылать и принимать (1) ip датаграммы для ip модуля, (2) arp запросы и отклики для arp модуля, и (3) rarp запросы и отклики для rarp модуля. tcp/ip поддерживает различные канальные уровни, в зависимости от того какой тип сетевого аппаратного обеспечения используется: ethernet, token ring, fddi (fiber distributed data interface), последовательные линии rs-232, и так далее. в этой главе мы подробно рассмотрим канальный уровень ethernet, два специализированных канальных уровня для последовательных интерфейсов (slip и ppp) и драйвер loopback, который присутствует практически во всех реализациях. ethernet и slip это канальные уровни, используемые для большинства примеров в данной книге. также мы рассмотрим максимальный блок передачи (mtu - maximum transmission unit), который является характеристикой канального уровня и к которой мы обращаемся много раз в этой главе и в следующих. также мы покажем некоторые расчеты, с помощью которых можно выбрать mtu для последовательной линии. ethernet и ieee 802 инкапсуляция термин ethernet обычно означает стандарт, опубликованный в 1982 году компаниями digital equipment corp., intel corp., и xerox corp. в настоящее время это основная технология применяемая в локальных сетях использующих tcp/ip. в ethernet используется метод доступа, называемый csma/cd, что обозначает наличие несущей (carrier sense), множественный доступ (multiple access) с определением коллизий (collision detection). обмен осуществляется со скоростью 10 мбит/сек, с использованием 48-битных адресов. несколько лет спустя комитет 802 института инженеров по электротехнике и радиоэлектронике (ieee - institute of electrical and electronics engineers) опубликовал отличающийся набор стандартов. 802.3 описывает полный набор сетей csma/cd, 802.4 описывает сети с передачей маркера и 802.5 описывает сети token ring. общим для всех них является стандарт 802.2, который определяет управление логическим каналом (llc - logical link control) и который является общим для большинства сетей 802. к сожалению, комбинация 802.2 и 802.3 определяет форматы фрейма отличные от ethernet ([stallings 1987] описывает все детали стандартов ieee 802). в мире tcp/ip инкапсуляция ip датаграмм определена в rfc 894 [hornig 1984] для сетей ethernet и в rfc 1042 [postel and reynolds 1988] для сетей ieee 802. в host requirements rfc к каждому компьютеру, подключенному к internet через кабель ethernet 10 мбит/сек, предъявляются следующие требования:
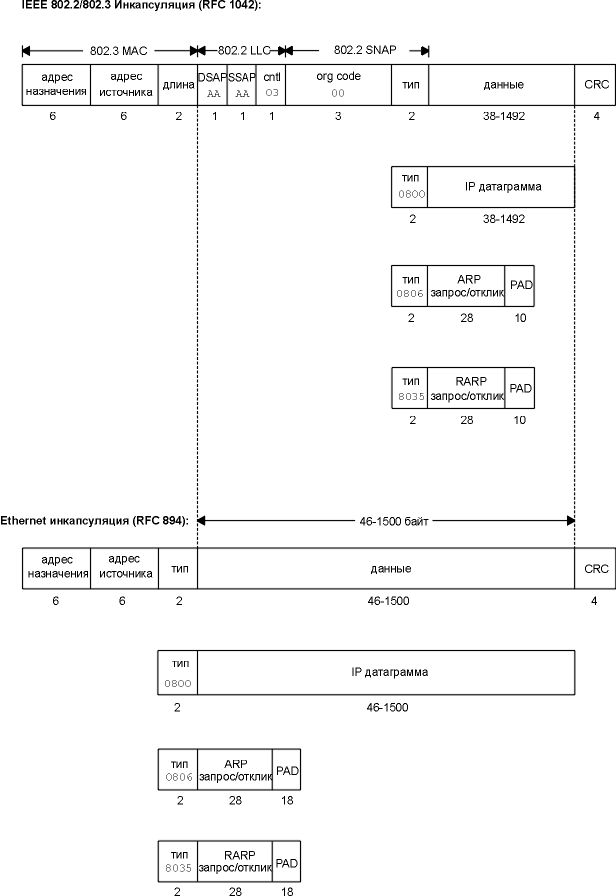
наиболее широко используется инкапсуляция rfc 894. на рисунке 2.1 показаны два различных метода инкапсуляции. цифры под каждым квадратиком на рисунке это размер в байтах. в обоих форматах фрейма используется 48-битовый (6-байтовый) формат представления адресов источника и назначения (802.3 позволяет использование 16-битных адресов, однако обычно используются 48-битные). это как раз то, что мы называем по тексту аппаратными адресами (hardware addresses). протоколы arp и rarp (см. главу 4 и главу 5) устанавливают соответствие между 32-битными ip адресами и 48-битными аппаратными адресами. следующие 2 байта в этих форматах фрейма различаются. поле длины (length) 802 содержит количество следующих за ним байтов, однако не содержит в конце контрольной суммы. поле тип (type) в ethernet определяет тип данных, которые следуют за ним. во фрейме 802 то же поле типа (type) появляется позже в заголовке протокола доступа к подсети (snap - sub-network access protocol). к счастью, величины, находящиеся в поле длины (length) 802, никогда не совпадают с величинами, находящимися в поле типа (type) ethernet, поэтому эти два формата фрейма легко различимы. во фрейме ethernet данные следуют сразу после поля тип (type), тогда как во фрейме 802 за ним следуют 3 байта llc 802.2 и 5 байт snap 802.2. поля dsap (точка доступа к сервису назначения - destination service access point) и ssap (точка доступа к сервису источника - source service access point) оба установлены в 0xaa. поле ctrl установлено в 3. следующие 3 байта, org code установлены в 0. затем идет 2-байтовое поле тип (type), такое же, как мы видели в формате фрейма ethernet (дополнительные значения, которые могут появиться в поле типа, описаны в rfc 1340 [reynolds and postel 1992]). поле контрольной суммы (crc) определяет ошибки, возникшие при транспортировке фрейма (также оно иногда называется fcs или последовательность контроля фрейма - frame check sequence). минимальный размер фреймов 802.3 и ethernet требует, чтобы размер данных был хотя бы 38 байт для 802.3 или 46 байт для ethernet. чтобы удовлетворить этому требованию, иногда вставляются байты заполнения, для того чтобы фрейм был соответствующей длины. мы еще столкнемся с минимальным размером, когда будем рассматривать движение пакетов по кабелям. также мы еще не раз обратимся к инкапсуляции ethernet, потому что это, пожалуй, самая широко распространенная форма инкапсуляции. рисунок 2.1 инкапсуляция ieee 802.2/802.3 (rfc 1042) и инкапсуляция ethernet (rfc 894). rfc 893 [leffler and karels 1984] описывает другую форму инкапсуляции, которая используется в ethernet и называется инкапсуляция завершителей (trailer encapsulation). с ранними версиями системы bsd на dec vax проводился эксперимент, который должен был увеличить производительность путем изменения порядка полей в ip датаграмме. поля с переменной длиной, которые находились в начале данных фрейма ethernet (ip заголовок и tcp заголовок), переносились в конец, сразу после контрольной суммы. это позволяет данным, находящимся во фрейме, быть спланированными в аппаратную страницу с сохранением копии в памяти, когда данные копируются в ядро. данные tcp, которые кратны 512 байтам, могут быть перемещены путем манипулирования страницами таблиц ядра. два компьютера договариваются об использовании инкапсуляции завершителей, пользуясь расширением arp. для этих фреймов определены различные значения типа фрейма ethernet. в настоящее время инкапсуляция завершителей не применяется, поэтому мы не будем приводить примеров. читатели, которые интересуются этой темой, могут обратиться к rfc 893 или разделу 11.8 [leffler et al. 1989] за более подробной информацией. slip: ip по последовательной линии slip - это простая форма инкапсуляции ip датаграмм для последовательной линии, которая описана в rfc 1055 [romkey 1988]. slip стал широко использоваться для подключения домашних систем к internet с того момента, когда практически на каждом компьютере появился последовательный порт rs-232, а также появились высокоскоростные модемы. формирование фреймов с использованием slip подчиняется следующим правилам.
на рисунке 2.2 показан пример создания подобных фреймов, при этом в исходной ip датаграмме появляются один end символ и один esc символ. в этом примере количество байт, переданных по последовательной линии, равно длине ip датаграммы плюс 4. slip использует довольно простой метод организации фрейма. существуют несколько правил, соблюдая которые можно работать со slip.
рисунок 2.2 инкапсуляция slip.
из нашего вступления достаточно запомнить то, что slip это очень популярный и широко используемый протокол. история slip начинается с 1984 года, когда рик адамс (rick adams) разработал его в 4.2bsd. популярность этого протокола постепенно росла, параллельно с ней росла скорость и надежность работы модемов. в конце концов появились свободно распространяемые разработки, а в настоящее время большинство поставщиков продают и поддерживают этот протокол. slip с компрессией (cslip) так как линии slip как правило медленные (19200 бит/сек или меньше) и часто используют для диалогового трафика (как, например, telnet и rlogin, оба из которых используют tcp), возникает необходимость уменьшить tcp пакеты, проходящие по slip каналу. для того чтобы перенести один байт данных, требуется 20 байт ip заголовков и 20 байт tcp заголовков, то есть вместе 40 байт (в разделе "интерактивный ввод" главы 19 показывается поток этих маленьких пакетов при вводе простых команд в течение сессии rlogin). после того как было определено, что с меньшими пакетами достигается большая производительность, новые версии slip стали называться cslip, что означает сжатый slip, который описан в rfc 1044 [jacobson 1990a]. cslip обычно уменьшает 40-байтовый заголовок до 3-5 байт. cslip поддерживает до 16 tcp соединений на каждом конце канала и знает, что каждое поле в двух заголовках для данного соединения обычно не изменяется. для тех полей, которые все же изменяются, изменения заключаются в небольшом увеличении. подобные уменьшенные заголовки значительно улучшают время отклика при диалоговой работе. большинство разработок slip в настоящее время поддерживают cslip. оба slip канала в подсети, приведенной на рисунке 1.11, являются каналами cslip. ppp: протокол точка-точка (point-to-point) ppp, протокол точка-точка, устраняет все недостатки slip. ppp состоит из трех компонентов.
rfc 1548 [simpson 1993] описывает метод инкапсуляции, который будет использоваться в протоколе управления каналом. rfc 1332 [mcgregor 1992] описывает протокол управления сетью для ip. формат ppp фреймов был выбран таким образом, чтобы напоминать стандарт iso hdlc (high-level data link control) . на рисунке 2.3 показан формат фреймов ppp.
рисунок 2.3 формат фреймов ppp.
каждый фрейм начинается и заканчивается с байта флаг (flag), значение которого равно 0x7e. затем следует байт адреса (address), значение которого всегда 0xff, и затем байт управления (control), значение которого 0x03. затем следует поле протокола (protocol), функции которого напоминают функции поля типа (type) в ethernet. значение 0x0021 обозначает что в информационном (information) поле ip датаграмма, значение 0xc021 означает что в информационном поле данные управления каналом, а значение 0x8021 означает - данные управления сетью. поле контрольной суммы (crc) используется для определения ошибок во фрейме. так как байт со значением 0x7e является символом flag, ppp необходимо экранировать этот байт когда он появляется в информационном поле. в последовательных каналах это делается аппаратным путем с использованием техники, называемой битовым заполнением (bit stuffing [tanenbaum 1989]). в асинхронных каналах специальный байт 0x7d используется в качестве символа экранирования (escape символ). если escape символ появляется во фрейме ppp, в следующем символе шестой бит инвертируется следующим образом:
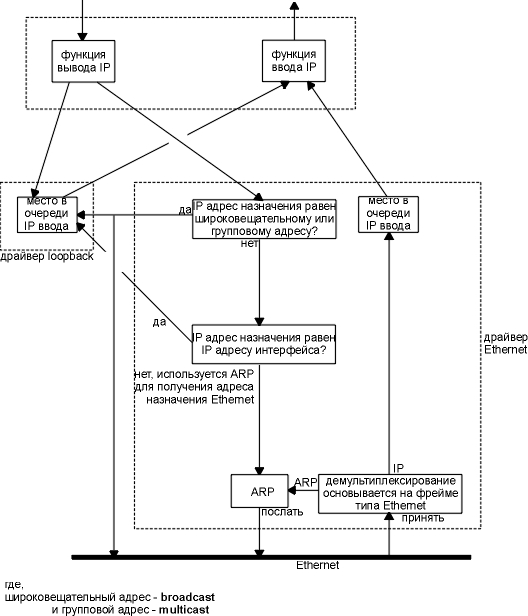
так как ppp, как и slip, часто используется на медленных последовательных каналах, уменьшение количества байт во фрейме значительно уменьшает задержку работы диалоговых приложений. с использованием протокола управления каналом большинство реализаций договариваются об исключении постоянных полей флага (flag) и адреса (address), для того чтобы уменьшить размер поля протокола (protocol) с 2 байтов до 1 байта. однако, если мы сравним ppp фрейм и slip фрейм (рисунок 2.2), мы увидим что ppp добавляет 3 дополнительных байта: 1 байт к полю протокола (protocol) и 2 байта к контрольной сумме (crc). в дополнение, с использованием протокола управления ip каналом, большинство реализаций договариваются об использовании алгоритма van jacobson для сжатия заголовка (идентично сжатию cslip), чтобы уменьшить размер ip и tcp заголовков. в общем случае, ppp имеет следующие преимущества перед slip: (1) поддерживает несколько протоколов на одной последовательной линии, не только ip датаграммы, (2) высчитывает контрольную сумму для каждого фрейма, (3) динамически договаривается об ip адресах для каждой оконечной системы (с использованием протокола управления ip каналом), (4) осуществляет сжатие заголовков tcp и ip так же как в cslip, и (5) использует протокол управления каналом для установления договоренности о большинстве характеристик канала. цена, которую мы платим за эти возможности, это и есть три дополнительных байта, которые появляются во фрейме, несколько фреймов, которые используются для установления договоренности при установлении канала, и несколько более сложная реализация. несмотря на все добавочные преимущества ppp над slip, на сегодняшний день пользователей slip значительно больше, чем пользователей ppp. когда ppp станет более доступен (когда его начнут поддерживать производители), он скорее всего заменит собой slip. интерфейс loopback большинство реализаций поддерживают интерфейс loopback, который позволяет клиенту и серверу на одном и том же компьютере общаться друг с другом используя tcp/ip. для интерфейса loopback зарезервирована сеть класса а с идентификатором 127. по договоренности большинство систем добавляют ip адрес 127.0.0.1 для этого интерфейса и дают ему имя localhost. ip датаграмма, посылаемая в интерфейс loopback, не попадает в сеть. мы можем решить, что транспортный уровень распознает, что удаленный адрес - это адрес loopback и каким-либо образом сокращает процесс обработки датаграммы. однако этого не происходит. осуществляется полная обработка данных на транспортном и сетевом уровнях, после чего ip датаграмма направляется по петле назад, когда выходит вниз из сетевого уровня. на рисунке 2.4 показана упрощенная диаграмма того, как loopback интерфейс обрабатывает ip датаграммы. рисунок 2.4 обработка ip датаграмм интерфейсом loopback.
на этом рисунке необходимо обратить внимание на следующее:
может показаться неэффективным то что транспортный и ip уровни обрабатывают данные, которые посылаются по петле. однако это упрощает разработку, потому что интерфейс loopback для сетевого уровня выглядит просто как еще один канальный уровень. сетевой уровень направляет датаграммы в интерфейс loopback как в любой другой канальный уровень, а затем интерфейс loopback помещает датаграммы обратно во входную очередь ip. другой интересный момент, который можно увидеть на рисунке 2.4, заключается в том, что ip датаграммы, посланные на один из собственных адресов хоста, обычно не попадают в соответствующую сеть. в комментариях к некоторым bsd драйверам ethernet устройств указывается, что большинство интерфейсных плат ethernet не способны читать свою собственную передачу. так как хост должен обрабатывать ip датаграммы, которые он посылает самому себе, такая обработка пакетов, как показано на рисунке 2.4, это простейший путь добиться этого. 4.4bsd имеет переменную useloopback (по умолчанию устанавливается ее в 1). если эта переменная установлена в 0, драйвера ethernet посылают локальные пакеты в сеть, вместо того чтобы посылать их в драйвер loopback. это может работать, а может и не работать, в зависимости от того, какая установлена интерфейсная плата ethernet и какой драйвер. mtu как мы видели на рисунке 2.1, существуют ограничения, накладываемые на размер фрейма для ethernet инкапсуляции и инкапсуляции 802.3. ограничение накладывается на количество байтов данных в 1500 и 1492 соответственно. эта характеристика канального уровня называется максимальный блок передачи (mtu - maximum transmission unit). большинство типов сетей определяют верхний предел. если ip хочет отослать датаграмму, которая больше чем mtu канального уровня, осуществляется фрагментация (fragmentation), при этом датаграмма разбивается на меньшие части (фрагменты). каждый фрагмент должен быть меньше чем mtu. мы обсудим ip фрагментацию в разделе "фрагментация ip" главы 11. на рисунке 2.5 приведен список некоторых типичных значений mtu, взятых из rfc 1191 [mogul and deering 1990]. здесь приведены mtu для каналов точка-точка (таких как slip или ppp), однако они не являются физической характеристикой среды передачи. это логическое ограничение, при соблюдении которого обеспечивается адекватное время отклика при диалоговом использовании. в разделе "вычисление загруженности последовательной линии" главы 2 мы рассмотрим, откуда берется это ограничение. в разделе "команда netstat" главы 3 мы воспользуемся командой netstat, чтобы определить mtu для определенного интерфейса.
рисунок 2.5 типичные значения максимальных блоков передачи (mtu).
когда общаются два компьютера в одной и той же сети, важным является mtu для этой сети. однако, когда общаются два компьютера в разных сетях, каждый промежуточный канал может иметь различные mtu. в данном случае важным является не mtu двух сетей, к которым подключены компьютеры, а наименьший mtu любого канала данных, находящегося между двумя компьютерами. он называется транспортным mtu (path mtu). транспортный mtu между любыми двумя хостами может быть не постоянным. mtu зависит от загруженности канала на настоящий момент. также он зависит от маршрута. маршрут может быть несимметричным (маршрут от a до b может быть совсем не тем, что маршрут от b к a), поэтому mtu может быть неодинаков для этих двух направлений. rfc 1191 [mogul and deering 1990] описывает механизм определения транспортного mtu (path mtu discovery mechanism). мы рассмотрим как функционирует этот механизм после того, как опишем фрагментацию icmp и ip. в разделе "icmp ошибки о недоступности" главы 11 мы подробно рассмотрим ошибку недоступности icmp, которая используется в этом механизме, а в разделе "определение транспортного mtu с использованием traceroute" главы 11 мы покажем версию программы traceroute, которая использует механизм определения транспортного mtu до пункта назначения. в разделах "определение транспортного mtu при использовании udp" главы 11 и "определение транспортного mtu" главы 24 показано, как функционируют udp и tcp, когда реализация поддерживает определение mtu. вычисление загруженности последовательной линии если скорость в линии составляет 9600 бит/сек, при этом 1 байт составляет 8 бит плюс 1 старт-бит и 1 стоп-бит, скорость линии будет 960 байт/сек. передача пакета размером 1024 байта с этой скоростью займет 1066 мс. если мы используем slip канал для диалогового приложения и одновременно с ним работает такое приложение как ftp, которое посылает или принимает пакеты по 1024 байт, мы должны ждать, так как среднее время задержки нашего интерактивного пакета составит 533 мс. это означает, что наш диалоговый пакет будет послан по каналу перед любым другим "большим" пакетом. большинство slip приложений предоставляют разделение пакетов по типу сервиса, отправляя диалоговый трафик перед трафиком передачи данных. диалоговый трафик это, как правило, telnet, rlogin и управляющая часть (пользовательские команды, но не данные) ftp. естественно, что такое разделение по сервисам несовершенно. оно не оказывает никакого воздействия на неинтерактивный трафик, который уже поставлен в очередь на передачу (например, последовательным драйвером). новые модели модемов, которые имеют большие буферы и позволяют сбуферизировать неинтерактивный трафик в буфере модема, что также сказывается на задержке диалогового трафика.
ожидание в 533 мс неприемлемо для диалогового ответа. с точки зрения человеческого фактора мы знаем, что неприемлемой является задержка дольше чем 100-200 мс [jacobson 1990a]. под задержкой подразумевается время между отправкой пакета и возвращением отклика (как правило, эхо символа). уменьшение mtu в канале slip до 256 означает, что максимальное время, в течение которого канал может быть занят одним фреймом, составляет 266 мс, и половина от этого (наше среднее время ожидания) составляет 133 мс. это лучше, однако до сих пор не идеально. причина, по которой мы выбрали это значение (как сравниваются 64 и 128), заключается в том, чтобы обеспечить лучшее использование канала для передачи данных (как, например, при передаче большого файла). в случае cslip фрейма размером 261 байт с заголовком размером в 5 байт (256 байт данных), 98,1% линии используются для передачи данных и 1,9% на заголовки. уменьшение mtu меньше чем 256 уменьшает максимальное значение пропускной способности линии, которую мы можем получить при передаче данных. значение mtu равное 296 для канала точка-точка (рисунок 2.5), подразумевает 256 байт данных и 40 байт tcp и ip заголовков. так как mtu это величина, о которой ip узнает от канального уровня, это значение должно включать в себя стандартные заголовки tcp и ip. именно таким образом ip принимает решение о фрагментации. ip ничего не знает о сжатии заголовков, которое осуществляются cslip. наш расчет средней задержки (половина того времени, которое требуется на передачу фрейма максимального размера) имеет отношение только к каналу slip (или каналу ppp), который используется для передачи интерактивного трафика и трафика данных. когда идет обмен только интерактивным трафиком, время передачи одного байта данных в каждом направлении (в случае сжатого 5-байтового заголовка) составляет примерно 12,5 мс, при скорости 9600 бит/сек. это хорошо укладывается в диапазон 100-200 мс, о котором мы упоминали ранее. также заметьте, что сжатие заголовков с 40 до 5 байт уменьшает время задержки для одного байта с 85 до 12,5 мс. к сожалению, эти расчеты становятся не совсем верными, когда используется коррекция ошибок и сжатие в модемах. сжатие в модемах уменьшает количество байт, которые посылаются по линии, однако исправление ошибок может увеличить время передачи этих байт. однако эти расчеты дают нам исходную точку, для того чтобы принять разумное решение. в следующих главах мы будем использовать эти расчеты для последовательных линий, чтобы определить некоторые величины таймеров, которые используются при передаче пакетов по последовательным линиям. в этой главе рассматривался самый нижний уровень из семейства протоколов internet, канальный уровень. мы рассмотрели различие между ethernet и ieee 802.2/802.3 инкапсуляциями, и инкапсуляцию, которая используется в slip и ppp. так как оба slip и ppp часто используются на медленных каналах, они предоставляют методы, для сжатия общих полей (которые практически всегда неизменны). при этом улучшается время отклика. интерфейс loopback существует в большинстве разработок. доступ к этому интерфейсу может быть получен через специальный адрес, обычно 127.0.0.1, или путем посылки ip датаграмм на один из собственных ip адресов хоста. данные, отправленные в loopback интерфейс, полностью обрабатываются транспортным уровнем и ip, когда они проходят по петле по стеку протоколов. мы описали важную характеристику большинства канальных уровней, mtu и соответствующую концепцию транспортного mtu. используя стандартный mtu для последовательных линий, мы вычислили временную задержку, которая существует в каналах slip и cslip. в этой главе рассматривается только несколько общих канальных технологий, используемых сегодня в tcp/ip. одна из причин, по которой tcp/ip успешно используется, это возможность работать поверх практически любых канальных технологий. упражнения
|